Open Robotic Data at Scale: Ecosystem Formation and Implications
TL;DR
Open robotic data has consolidated around three dominant ecosystems—OXE, LeRobot, and InternData-A1—which now define data scale, formats, and research baselines. Basic manipulation data is commoditized; future value lies in high-fidelity, physically complex, and training-ready datasets.
The Panorama of Open Data: From Fragmentation to Consolidation
The current state of robot learning datasets on the Hugging Face Hub vividly illustrates the ongoing paradigm shift in embodied intelligence research-from scattered, institution-specific collections toward large-scale, standardized, and community-driven unification. An analysis of the Hub’s trending datasets filtered by the keyword “robot” and related repositories reveals a pronounced Matthew effect: a small number of flagship initiatives have captured the overwhelming majority of attention, downloads, and citations, while hundreds of smaller datasets struggle for visibility.
This consolidation is not accidental; it reflects both technical necessity (the need for scale and standardization to train generalist robot policies) and ecosystem dynamics (the gravitational pull of well-supported, framework-aligned projects).
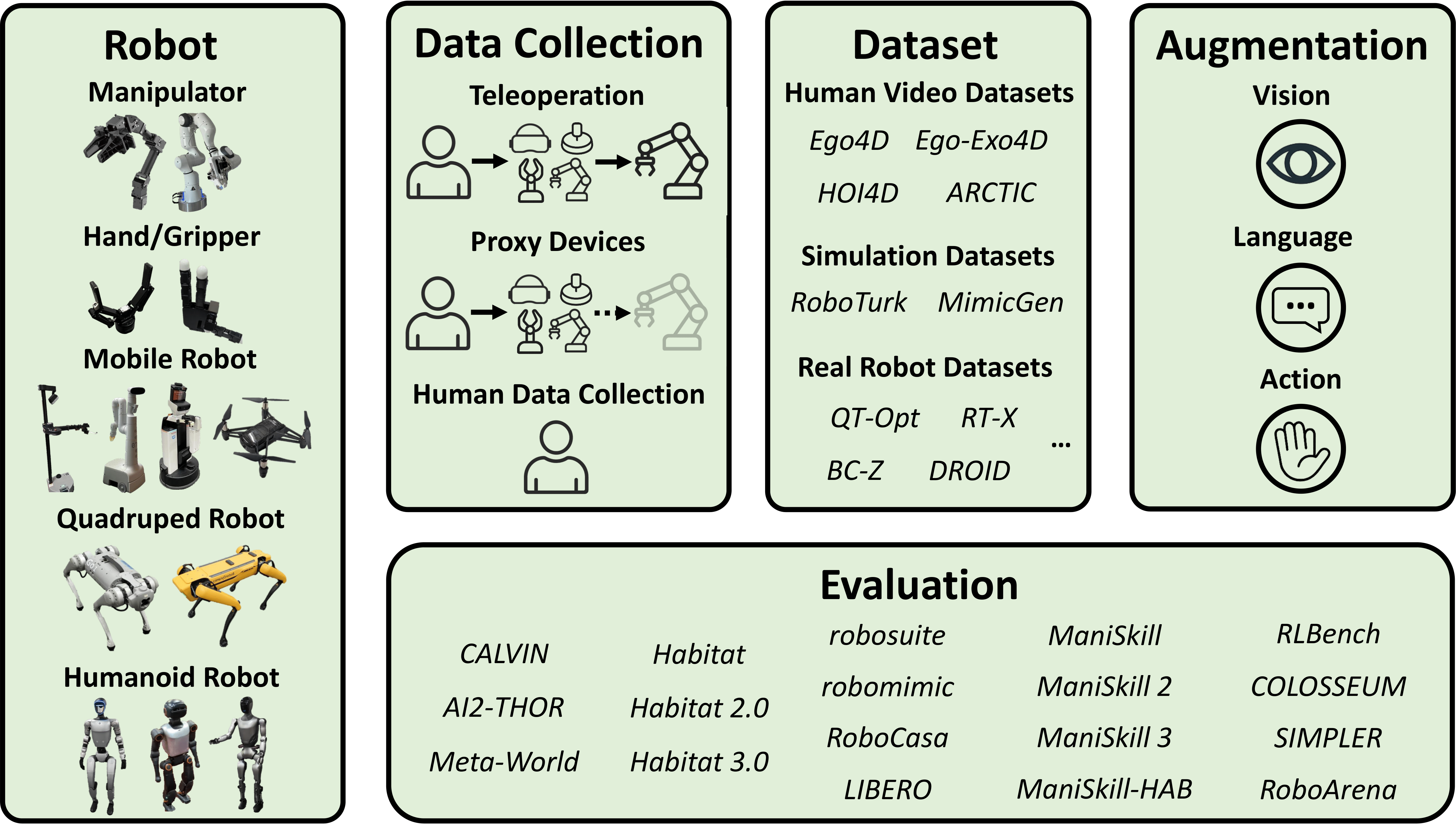
1. Core Data Ecosystems
The open data landscape coalesced around three dominant ecosystems, each occupying a distinct technical, philosophical, and industrial niche. These “black-hole” projects now define the de facto baselines for robot foundation models, rendering most pre-2023 individual datasets effectively obsolete for cutting-edge research.
1.1 Open X-Embodiment (OXE): The ImageNet Moment for Robotics
The Open X-Embodiment collection [1] represents the most ambitious and influential attempt to date to create a universal substrate for embodied AI. Launched in late 2023 by a consortium of 34 leading robotics laboratories, OXE is not a single dataset but a carefully curated federation of over 60 existing datasets, unified under a common schema.
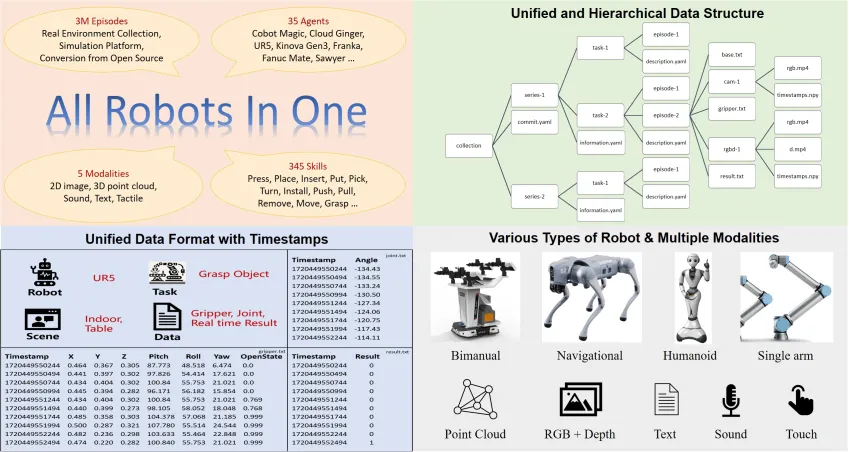
Key characteristics:
- Scale and Embodiment Diversity: >1 million real-world trajectories spanning 22 distinct robot embodiments-from industrial manipulators (KUKA, Franka Emika) to mobile manipulators (Hello Robot Stretch), low-cost arms (WidowX), and legged systems (Unitree A1, Boston Dynamics Spot).
- Standardization: All data is converted to the RLDS format built on TensorFlow Datasets and Apache Arrow. This enables seamless loading, sharding, and mixing across datasets, making OXE the foundational pre-training corpus for Google DeepMind’s RT-1-X, RT-2-X, and Octo models [2].
- Impact: OXE has effectively commoditized medium-quality teleoperated manipulation data. Tasks such as pick-and-place, drawer opening, and simple assembly using single arms are now “solved” at the data level.
Strategic implication: The era of selling or gating basic real-world arm trajectories is over. Future commercial value will lie in high-precision expert data, long-horizon mobile manipulation in real homes, missing embodiments (humanoids, soft robots), or rich proprietary metadata.
1.2 The LeRobot Ecosystem
While OXE embodies the Google/TensorFlow-centric research paradigm, Hugging Face’s LeRobot project [3–5] has rapidly emerged as the de facto standard for the broader open-source and industry communities that prefer PyTorch.
LeRobot represents a comprehensive stack-datasets, models, training code, and evaluation suites—designed explicitly to lower the barrier to entry for real-world robot learning.
Technical innovations in data engineering:
- Storage Format Revolution: LeRobot Dataset v3.0 adopts Apache Parquet + compressed MP4/AV1, achieving 5–10× lower storage and dramatically faster loading than legacy formats.
- Flagship Datasets:
lerobot/droid_1.0.1[6]: ~76k episodes from 50+ teams, deliberately collected “in-the-wild” for maximum real-world variation.
lerobot/aloha_static_*andlerobot/aloha_mobile_*: High-precision bimanual and mobile-bimanual data from the Aloha 2 system [7].
Strategic implication: The data delivery standard has permanently shifted to Parquet+MP4. Any commercial provider still delivering ROS bags or raw videos is imposing unnecessary technical debt on customers.
1.3 The Rise of Large-Scale Synthetic Data: InternData-A1
A third major force is the emergence of high-fidelity synthetic data at unprecedented scale, exemplified by InternData-A1 from Shanghai AI Laboratory and collaborators [8].
Key specifications:
- Scale: 630k trajectories, equivalent to 7,433 hours of robot experience.
- Physical Diversity: Includes rigid bodies, articulated objects, fluids, granules, and deformable materials (cloth, ropes)-domains where simulation has historically been weakest.
- Generation Pipeline: Leverages advanced physics engines with domain randomization, photorealistic rendering, and automated curriculum generation.
Strategic implication: Synthetic data is rapidly displacing real data in the low-to-medium complexity regime. For tasks involving only rigid-body interactions, synthetic data now matches or exceeds real data in both quantity and controllable diversity. Real-world data retains irreducible value only in domains where simulation remains inaccurate—primarily fluids, thin-shell deformation, and highly contact-rich tasks under variable friction and compliance.
1.4 Challenges and Limitations of Large-Scale Synthetic Data
Although projects like InternData-A1 have pushed synthetic data to unprecedented scales and physical diversity, the technology remains constrained by fundamental limitations that prevent it from fully displacing real-world data collection in most commercially relevant regimes. A comprehensive October 2025 survey on the “reality gap” (Aljalbout et al., arXiv:2510.20808) confirms that, despite impressive engineering progress, the core discrepancies between simulation and physical reality have not been eliminated-they have merely been pushed into narrower, but still critically important, frontiers.
The reality gap can be taxonomized into four primary categories, each introducing systematic errors that policies inevitably exploit in simulation yet fail to handle in reality:
Dynamics Gap
The largest and most persistent source of failure. Even the best 2025-era physics engines (Isaac Sim 2025.2, MuJoCo 3.x with GPU-accelerated contact solvers, NVIDIA Warp + NeRD neural dynamics) struggle with chaotic or history-dependent phenomena, deformable and thin-shell objects, unmodeled actuator-environment couplings, and numerical integration errors that compound over long horizons (>10 s).
Result: Policies that work perfectly in simulation collapse during real contact-rich phases.
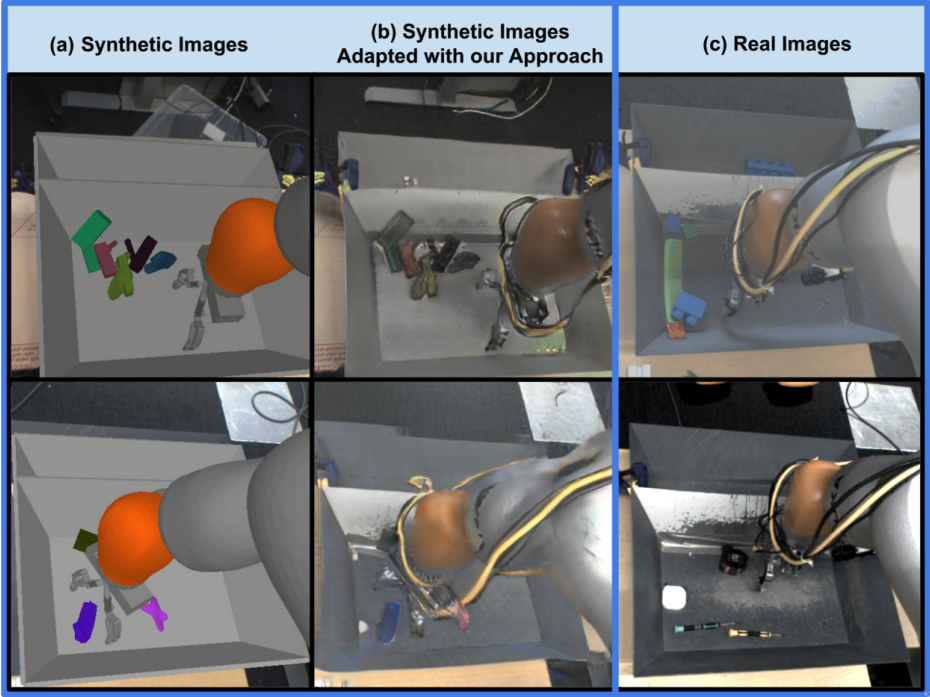
Perception and Sensing Gap
Synthetic rendering in 2025 has reached extraordinary photorealism via 3D Gaussian Splatting and video diffusion priors (e.g., RoboGen v2, OpenX-Embodiment-Synthetic), yet systematic artifacts remain: absence of real camera imperfections, incorrect noise models, and missing subsurface scattering, caustics, dust particles, and dynamic texture evolution.
Actuation and Low-Level Control Gap
Real robots have hidden controllers that drift over time due to wear. Even NVIDIA’s NeRD (CoRL 2025) requires per-robot fine-tuning in practice.
System Design and Environment Gap
Safety controllers, latency, and unmodeled floor compliance are rarely simulated accurately.

Current Mitigation Strategies and Their Limits
The field has converged on massive domain randomization + residual modeling, real-to-sim-to-real pipelines, hybrid training (90–99 % synthetic + 1–10 % real), and architectural innovations. Notable 2025 breakthroughs include NVIDIA’s R²D² suite (NeRD + Dexplore/RSE + VT-Refine) and scalable residual RL methods.
Despite these advances, the October 2025 survey concludes that zero-shot sim-to-real remains restricted to medium-complexity rigid-body tasks in controlled environments. For any application involving deformable objects, fluids, high-precision assembly, or operation in unstructured human homes, real-world data—particularly expert demonstrations with rich metadata—continues to command irreducible premium value.
Strategic implication for data providers: The commercial sweet spot in 2026–2028 will be hybrid datasets that combine massive synthetic scale with small, high-value real trajectories in the remaining “hard” domains (cloth, liquids, dense clutter, multi-step reasoning in diverse homes). Pure synthetic data, no matter how large, will not suffice for production-grade deployment in the foreseeable future.
Synthesis and Future Trajectory
The convergence of OXE (TensorFlow-scale unification), LeRobot (PyTorch-native accessibility), and InternData-A1 (synthetic scalability) signals that the fragmentation era of robot learning data is ending. We are entering a “post-dataset” phase where the primary research and commercial questions are no longer “which dataset?” but rather:
- How to most effectively mix real, synthetic, and distilled data?
- How to design metadata schemas that survive foundation model distillation?
- Which remaining embodiments and physical phenomena constitute critical bottlenecks?
The winners in the next 2–3 years will be those who can produce data that is simultaneously high-quality, standardization-compliant, and positioned in the shrinking set of domains where real-world collection still confers decisive advantage.
References
[1] Open X-Embodiment Collaboration. robotics-transformer-x.github.io
[2] Padalkar et al., “Open X-Embodiment: Robotic Learning Datasets and RT-X Models,” ICRA 2024
[3] Hugging Face LeRobot. huggingface.co/lerobot
[4] Lynch et al., “LeRobot: A Framework for Production-Ready Robot Learning,” 2024
[5] LeRobot Dataset v3.0 Specification. github.com/huggingface/lerobot
[6] DROID Dataset. huggingface.co/datasets/lerobot/droid_1.0.1
[7] Aloha Dataset. huggingface.co/datasets/lerobot/aloha
[8] InternData-A1, Shanghai AI Laboratory, 2025